上周五晚上8点,开开心心的等着产品验收完毕后就可以顺利上线。结果产品突然找到我说要加需求,并且维护这一块业务的同事已经下班走了,所以只有我来做。虽然内心一万头草泥马在狂奔,但是嘴里还是一口答应没问题。由于这一块业务很复杂并且我也不熟悉,加上还饿着肚子,在梳理代码逻辑的时候我差点崩溃了。需要修改的那个vue文件有几千行代码,迭代业务对应的ref变量有10多个watch。我光是梳理这些watch的逻辑就搞了很久,然后小心翼翼的在原有代码上面加上新的业务逻辑,不敢去修改原有逻辑(担心搞出线上bug背锅)。
首先我们来看一个例子:
{{ datalist }}
上面这个例子在template中渲染了datalist,当props.id更新时和初始化时从服务端异步获取datalist。当props.disablelist和props.type更新时,同步的计算出新的datalist。
代码逻辑流程图是这样的: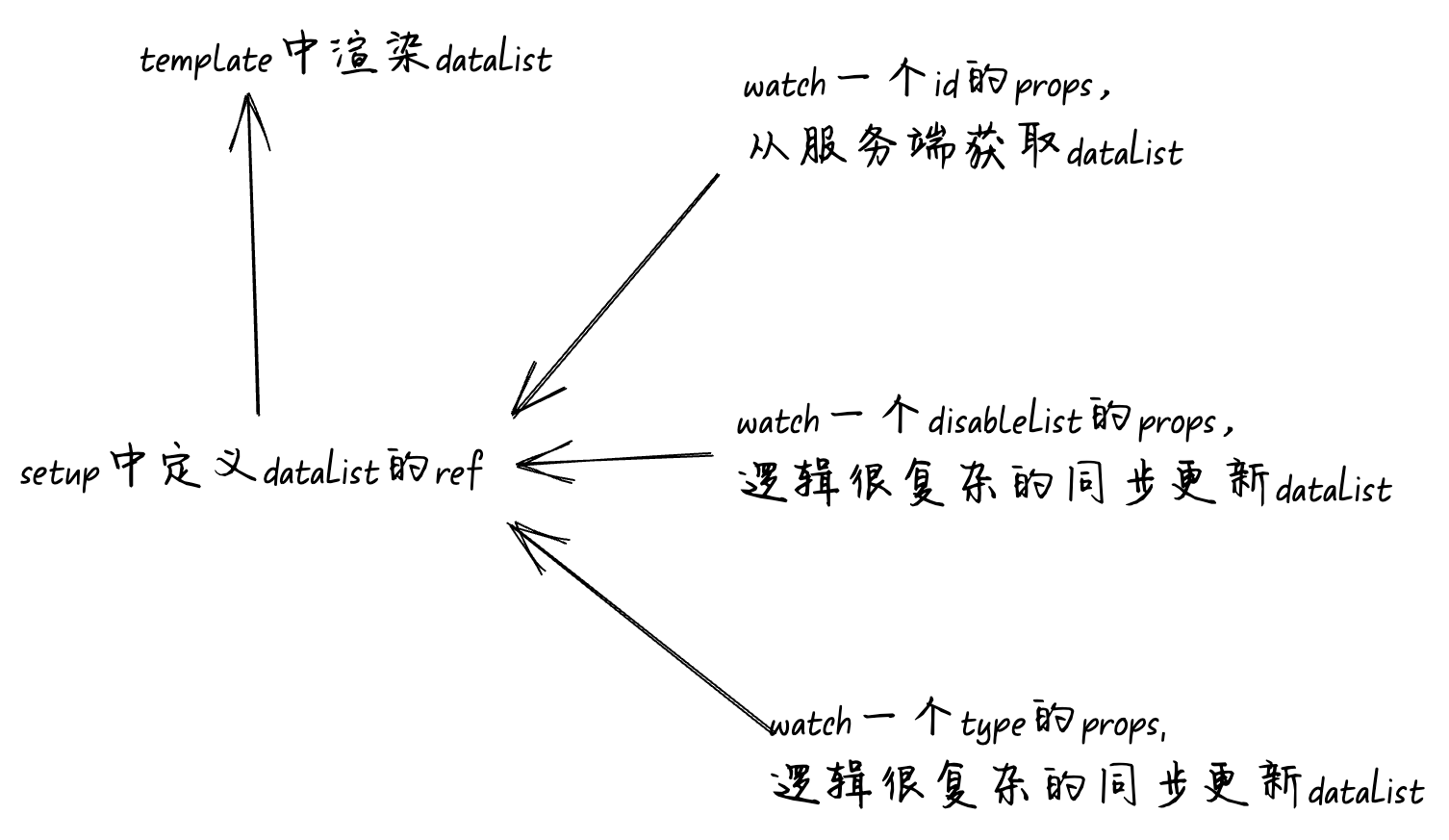
乍一看上面的代码没什么问题,但是当一个不熟悉这一块业务的新同学接手这一块代码时问题就出来了。
我们平时接手一个不熟悉的业务首先要找一个切入点,对于前端业务,切入点肯定是浏览器渲染的页面。在 vue 中,页面由模板渲染而来,找到模板中使用的响应式变量和他的来源,就能理解业务逻辑。以 datalist 变量为例,梳理datalist的来源基本就可以理清业务逻辑。
在我们上面的这个例子datalist的来源就是发散的,有很多个来源。首先是watch了props.id从服务端异步获取。然后是watch了props.disablelist和props.type,同步更新了datalist。这个时候一个不熟悉业务的同学接到产品需求要更新datalist的取值逻辑,他需要先熟悉datalist多个来源的取值逻辑,熟悉完逻辑后再分析我到底应该是在哪个watch上面去修改业务逻辑完成产品需求。
但是实际上我们维护别人的代码时(特别是很复杂的代码)一般都不愿意去改代码,而是在原有代码的基础上再去加上我们的代码。因为去改别人的复杂代码很容易搞出线上bug,然后背锅。所以在这里我们的做法一般都是再加一个watch,然后在这个watch中去实现产品最新的datalist业务逻辑。
watch(
() => props.xxx,
() => {
// 加上产品最新的业务逻辑
const newlist = getlistfromxxx(datalist.value);
datalist.value = newlist;
}
);
迭代几次业务后这个vue文件里面就变成了一堆watch,屎山代码就是这样形成的。当然不排除有的情况是故意这样写的,为的就是稳定自己在团队里面的地位,因为离开了你这坨代码没人敢动。
我们看了上面的反例,那么一个易维护的代码是怎么样的呢?我认为应该是下面这样的:
datalist在template中渲染,然后同步更新datalist,最后异步从服务端异步获取datalist,整个过程能够被穿成一条线。此时新来一位同学要去迭代datalist相关的业务,那么他只需要搞清楚产品的最新需求是应该在同步阶段去修改代码还是异步阶段去修改代码,然后在对应的阶段去加上对应的最新代码即可。
我们来看看上面的例子应该怎么优化成易维护的代码,上面的代码中datalist来源主要分为同步来源和异步来源。异步来源这一块我们没法改,因为从业务上来看props.id更新后必须要从服务端获取最新的datalist。我们可以将同步来源的代码全部摞到computed中。优化后的代码如下:
{{ renderdatalist }}
我们在template中渲染的不再是datalist变量,而是renderdatalist。renderdatalist是一个computed,在这个computed中包含了所有datalist同步相关的逻辑。代码逻辑流程图是这样的: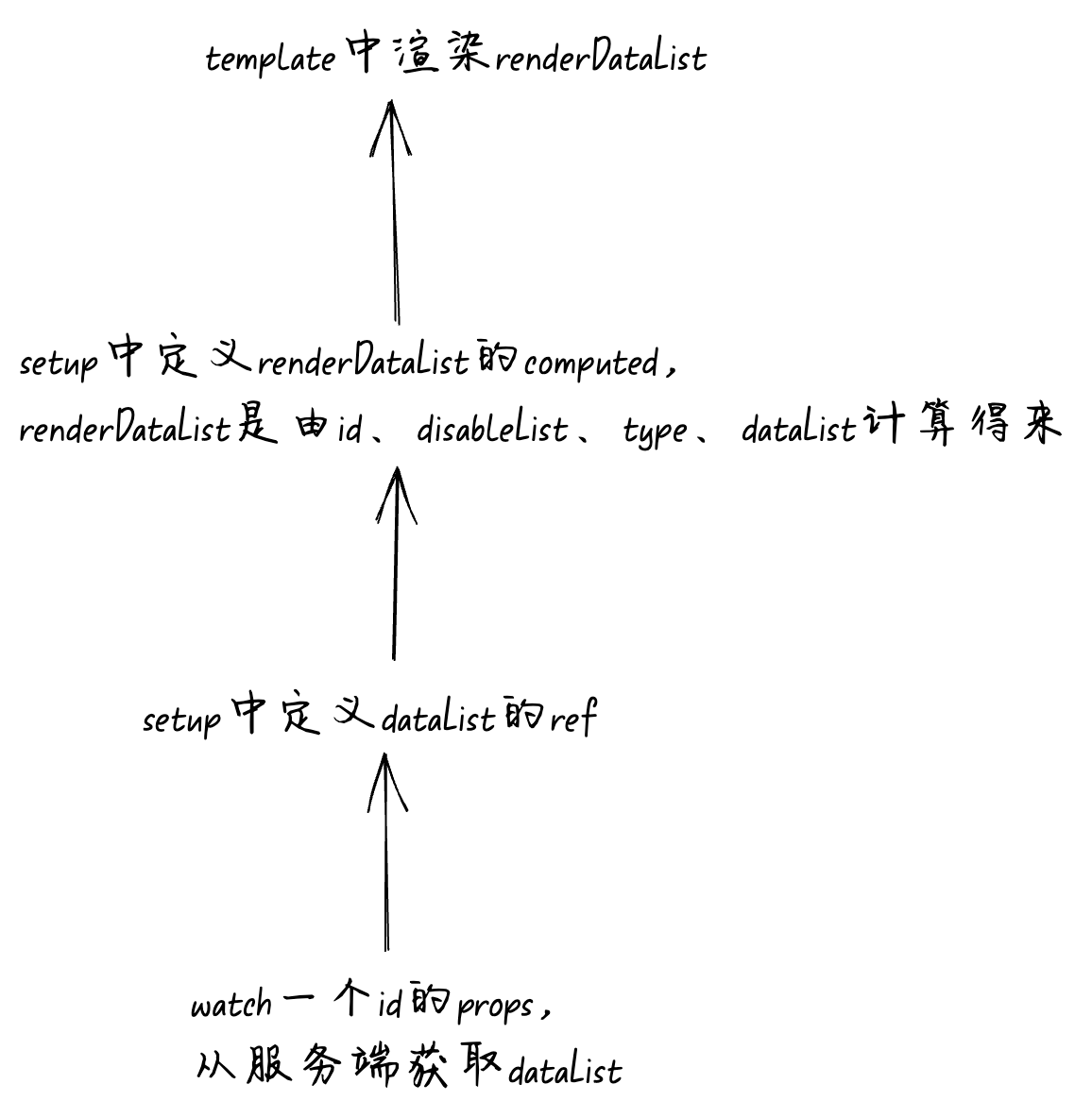
此时一位新同学接到产品需求要迭代datalist相关的业务,因为我们的整个业务逻辑已经变成了一条线,新同学就可以很快的梳理清楚业务逻辑。再根据产品的需求看到底应该是修改同步相关的逻辑还是异步相关的逻辑。下面这个是修改同步逻辑的demo:
const renderdatalist = computed(() => {
// 加上产品最新的业务逻辑
const xxxlist = getlistfromxxx(datalist.value);
// 根据disablelist计算出list
const newdatalist = getlistfromdisabledlist(xxxlist);
// 根据type计算出list
return getlistfromtype(newdatalist);
});
这篇文章介绍了watch主要分为两种使用场景,一种是当watch的值改变后需要同步更新渲染的datalist,另外一种是当watch的值改变后需要异步从服务端获取要渲染的datalist。如果不管同步还是异步都一股脑的将所有代码都写在watch中,那么后续接手的维护者要梳理datalist相关的逻辑就会非常痛苦。因为到处都是watch在更新datalist的值,完全不知道应该在哪个watch中去加上最新的业务逻辑,这种时候我们一般就会再新加一个watch然后在新的watch中去实现最新的业务逻辑,时间久了代码中就变成了一堆watch,维护性就变得越来越差。我们给出的优化方案是将那些同步更新datalist的watch代码全部摞到一个名为renderdatalist的computed,后续维护者只需要判断新的业务如果是同步更新datalist,那么就将新的业务逻辑写在computed中。如果是要异步更新datalist,那么就将新的业务逻辑写在watch中。
如果我的文章对你有点帮助,欢迎关注公众号:【前端欧阳】,文章在公众号首发。你的支持就是我创作的最大动力,感谢感谢!
