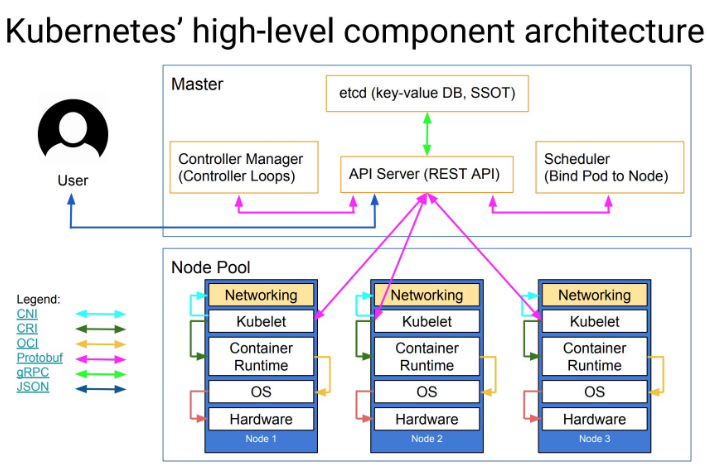
在 kubernetes 架构中, 是一个永不休止的控制回路组件,其负责控制集群资源的状态。通过监控 kube-apiserver 的资源状态,比较当前资源状态和期望状态,如果不一致,更新 kube-apiserver 的资源状态以保持当前资源状态和期望状态一致。
下面从源码角度分析 kube-controller-manager 的工作方式。
kube-controller-manager 使用 作为应用命令行框架,和 kube-scheduler,kube-apiserver 初始化过程类似,其流程如下:
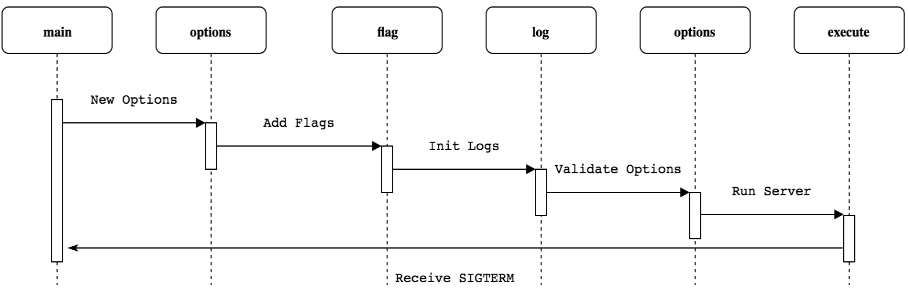
这里,简要给出初始化代码示例:
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
func newcontrollermanagercommand() *cobra.command {
// 创建选项
s, err := options.newkubecontrollermanageroptions()
...
cmd := &cobra.command{
...
rune: func(cmd *cobra.command, args []string) error {
...
// 根据选项,创建配置
c, err := s.config(knowncontrollers(), controllersdisabledbydefault(), controlleraliases())
if err != nil {
return err
}
...
return run(context.background(), c.complete())
},
...
}
...
}
进入 run 函数,看 kube-controller-manager 是怎么运行的。
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
func run(ctx context.context, c *config.completedconfig) error {
...
run := func(ctx context.context, controllerdescriptors map[string]*controllerdescriptor) {
// 创建上下文
controllercontext, err := createcontrollercontext(logger, c, rootclientbuilder, clientbuilder, ctx.done())
if err != nil {
logger.error(err, "error building controller context")
klog.flushandexit(klog.exitflushtimeout, 1)
}
// 开始控制器,这是主运行逻辑
if err := startcontrollers(ctx, controllercontext, controllerdescriptors, unsecuredmux, healthzhandler); err != nil {
logger.error(err, "error starting controllers")
klog.flushandexit(klog.exitflushtimeout, 1)
}
// 启动 informer
controllercontext.informerfactory.start(stopch)
controllercontext.objectormetadatainformerfactory.start(stopch)
close(controllercontext.informersstarted)
<-ctx.done()
}
// no leader election, run directly
if !c.componentconfig.generic.leaderelection.leaderelect {
// 创建控制器描述符
controllerdescriptors := newcontrollerdescriptors()
controllerdescriptors[names.serviceaccounttokencontroller] = satokencontrollerdescriptor
run(ctx, controllerdescriptors)
return nil
}
...
}
和 kube-scheduler 类似,kube-controller-manager 也是多副本单实例运行的组件,需要 leader election 作为 leader 组件运行。这里不过多介绍,具体可参考 。
运行控制器管理器。首先,在 newcontrollerdescriptors 中注册资源控制器的描述符。
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
func newcontrollerdescriptors() map[string]*controllerdescriptor {
register := func(controllerdesc *controllerdescriptor) {
...
controllers[name] = controllerdesc
}
...
// register 函数注册资源控制器
register(newendpointscontrollerdescriptor())
register(newendpointslicecontrollerdescriptor())
register(newendpointslicemirroringcontrollerdescriptor())
register(newreplicationcontrollerdescriptor())
register(newpodgarbagecollectorcontrollerdescriptor())
register(newresourcequotacontrollerdescriptor())
...
return controllers
}
# kubernetes/cmd/kube-controller-manager/app/apps.go
func newreplicasetcontrollerdescriptor() *controllerdescriptor {
return &controllerdescriptor{
name: names.replicasetcontroller,
aliases: []string{"replicaset"},
initfunc: startreplicasetcontroller,
}
}
每个资源控制器描述符包括 initfunc 和启动控制器函数的映射。
在 run 中 startcontrollers 运行控制器。
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
func startcontrollers(ctx context.context, controllerctx controllercontext, controllerdescriptors map[string]*controllerdescriptor,
unsecuredmux *mux.pathrecordermux, healthzhandler *controllerhealthz.mutablehealthzhandler) error {
...
// 遍历获取资源控制器描述符
for _, controllerdesc := range controllerdescriptors {
if controllerdesc.requiresspecialhandling() {
continue
}
// 运行资源控制器
check, err := startcontroller(ctx, controllerctx, controllerdesc, unsecuredmux)
if err != nil {
return err
}
if check != nil {
// healthchecker should be present when controller has started
controllerchecks = append(controllerchecks, check)
}
}
...
return nil
}
func startcontroller(ctx context.context, controllerctx controllercontext, controllerdescriptor *controllerdescriptor,
unsecuredmux *mux.pathrecordermux) (healthz.healthchecker, error) {
...
// 获取资源控制器描述符的启动函数
initfunc := controllerdescriptor.getinitfunc()
// 启动资源控制器
ctrl, started, err := initfunc(klog.newcontext(ctx, klog.loggerwithname(logger, controllername)), controllerctx, controllername)
if err != nil {
logger.error(err, "error starting controller", "controller", controllername)
return nil, err
}
...
}
kubernetes 有多个控制器,这里以 replicaset 控制器为例,介绍控制器是怎么运行的。
进入 replicaset 控制器的 initfunc 函数运行控制器。
# kubernetes/cmd/kube-controller-manager/app/apps.go
func startreplicasetcontroller(ctx context.context, controllercontext controllercontext, controllername string) (controller.interface, bool, error) {
go replicaset.newreplicasetcontroller(
klog.fromcontext(ctx),
controllercontext.informerfactory.apps().v1().replicasets(),
controllercontext.informerfactory.core().v1().pods(),
controllercontext.clientbuilder.clientordie("replicaset-controller"),
replicaset.burstreplicas,
).run(ctx, int(controllercontext.componentconfig.replicasetcontroller.concurrentrssyncs))
return nil, true, nil
}
运行 initfunc 实际上运行的是 startreplicasetcontroller。startreplicasetcontroller 启动一个 goroutine 运行 replicaset.newreplicasetcontroller 和 replicasetcontroller.run,replicaset.newreplicasetcontroller 创建了 informer 的 eventhandler,replicasetcontroller.run 负责对 eventhandler 中加入队列的资源做处理。示意图如下:
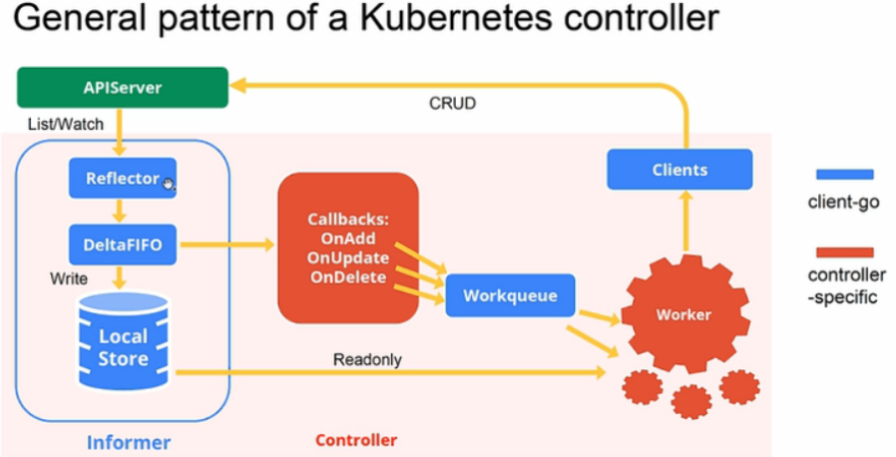
首先,进入 replicaset.newreplicasetcontroller 查看函数做了什么。
# kubernetes/pkg/controller/replicaset/replica_set.go
func newreplicasetcontroller(logger klog.logger, rsinformer appsinformers.replicasetinformer, podinformer coreinformers.podinformer, kubeclient clientset.interface, burstreplicas int) *replicasetcontroller {
...
return newbasecontroller(logger, rsinformer, podinformer, kubeclient, burstreplicas,
apps.schemegroupversion.withkind("replicaset"),
"replicaset_controller",
"replicaset",
controller.realpodcontrol{
kubeclient: kubeclient,
recorder: eventbroadcaster.newrecorder(scheme.scheme, v1.eventsource{component: "replicaset-controller"}),
},
eventbroadcaster,
)
}
func newbasecontroller(logger klog.logger, rsinformer appsinformers.replicasetinformer, podinformer coreinformers.podinformer, kubeclient clientset.interface, burstreplicas int,
gvk schema.groupversionkind, metricownername, queuename string, podcontrol controller.podcontrolinterface, eventbroadcaster record.eventbroadcaster) *replicasetcontroller {
rsc := &replicasetcontroller{
groupversionkind: gvk,
kubeclient: kubeclient,
podcontrol: podcontrol,
eventbroadcaster: eventbroadcaster,
burstreplicas: burstreplicas,
expectations: controller.newuidtrackingcontrollerexpectations(controller.newcontrollerexpectations()),
queue: workqueue.newnamedratelimitingqueue(workqueue.defaultcontrollerratelimiter(), queuename),
}
rsinformer.informer().addeventhandler(cache.resourceeventhandlerfuncs{
addfunc: func(obj interface{}) {
rsc.addrs(logger, obj)
},
updatefunc: func(oldobj, newobj interface{}) {
rsc.updaters(logger, oldobj, newobj)
},
deletefunc: func(obj interface{}) {
rsc.deleters(logger, obj)
},
})
...
podinformer.informer().addeventhandler(cache.resourceeventhandlerfuncs{
addfunc: func(obj interface{}) {
rsc.addpod(logger, obj)
},
updatefunc: func(oldobj, newobj interface{}) {
rsc.updatepod(logger, oldobj, newobj)
},
deletefunc: func(obj interface{}) {
rsc.deletepod(logger, obj)
},
})
...
rsc.synchandler = rsc.syncreplicaset
return rsc
}
函数定义了 replicasetcontroller 和 podinformer,负责监控 kube-apiserver 中 replicaset 和 pod 的变化,根据资源的不同变动触发对应的 event handler。
接着,进入 run 查看函数做了什么。
# kubernetes/pkg/controller/replicaset/replica_set.go
func (rsc *replicasetcontroller) run(ctx context.context, workers int) {
...
// 同步缓存和 kube-apiserver 中获取的资源
if !cache.waitfornamedcachesync(rsc.kind, ctx.done(), rsc.podlistersynced, rsc.rslistersynced) {
return
}
for i := 0; i < workers; i {
// worker 负责处理队列中的资源
go wait.untilwithcontext(ctx, rsc.worker, time.second)
}
<-ctx.done()
}
func (rsc *replicasetcontroller) worker(ctx context.context) {
// worker 是永不停止的
for rsc.processnextworkitem(ctx) {
}
}
func (rsc *replicasetcontroller) processnextworkitem(ctx context.context) bool {
// 读取队列中的资源
key, quit := rsc.queue.get()
if quit {
return false
}
defer rsc.queue.done(key)
// 处理队列中的资源
err := rsc.synchandler(ctx, key.(string))
if err == nil {
rsc.queue.forget(key)
return true
}
...
return true
}
可以看到,rsc.synchandler 处理队列中的资源,rsc.synchandler 实际执行的是 replicasetcontroller.syncreplicaset。
理清了代码的结构,我们以一个删除 pod 示例看 kube-controller-manager 是怎么运行的。
1.1 删除 pod 示例
1.1.1 示例条件
创建 replicaset 如下:
# helm list
name namespace revision updated status chart app version
test default 1 2024-02-29 16:24:43.896757193 0800 cst deployed test-0.1.0 1.16.0
# kubectl get replicaset
name desired current ready age
test-6d47479b6b 1 1 1 10d
# kubectl get pods
name ready status restarts age
test-6d47479b6b-5k6cb 1/1 running 0 9d
删除 pod 查看 kube-controller-manager 是怎么运行的。
1.1.2 运行流程
删除 pod:
# kubectl delete pods test-6d47479b6b-5k6cb
删除 pod 后,podinformer 的 event handler 接受到 pod 的变化,调用 replicasetcontroller.deletepod 函数:
func (rsc *replicasetcontroller) deletepod(logger klog.logger, obj interface{}) {
pod, ok := obj.(*v1.pod)
...
logger.v(4).info("pod deleted", "delete_by", utilruntime.getcaller(), "deletion_timestamp", pod.deletiontimestamp, "pod", klog.kobj(pod))
...
rsc.queue.add(rskey)
}
replicasetcontroller.deletepod 将删除的 pod 加入到队列中。接着,worker 中的 replicasetcontroller.processnextworkitem 从队列中获取删除的 pod,进入 replicasetcontroller.syncreplicaset 处理。
func (rsc *replicasetcontroller) syncreplicaset(ctx context.context, key string) error {
...
namespace, name, err := cache.splitmetanamespacekey(key)
...
// 获取 pod 对应的 replicaset
rs, err := rsc.rslister.replicasets(namespace).get(name)
...
// 获取所有 pod
allpods, err := rsc.podlister.pods(rs.namespace).list(labels.everything())
if err != nil {
return err
}
// ignore inactive pods.
filteredpods := controller.filteractivepods(logger, allpods)
// 获取 replicaset 下的 pod
// 这里 pod 被删掉了,filteredpods 为 0
filteredpods, err = rsc.claimpods(ctx, rs, selector, filteredpods)
if err != nil {
return err
}
// replicaset 下的 pod 被删除
// 进入 rsc.managereplicas
var managereplicaserr error
if rsneedssync && rs.deletiontimestamp == nil {
managereplicaserr = rsc.managereplicas(ctx, filteredpods, rs)
}
...
}
继续进入 replicasetcontroller.managereplicas:
func (rsc *replicasetcontroller) managereplicas(ctx context.context, filteredpods []*v1.pod, rs *apps.replicaset) error {
diff := len(filteredpods) - int(*(rs.spec.replicas))
...
if diff < 0 {
logger.v(2).info("too few replicas", "replicaset", klog.kobj(rs), "need", *(rs.spec.replicas), "creating", diff)
...
successfulcreations, err := slowstartbatch(diff, controller.slowstartinitialbatchsize, func() error {
err := rsc.podcontrol.createpods(ctx, rs.namespace, &rs.spec.template, rs, metav1.newcontrollerref(rs, rsc.groupversionkind))
if err != nil {
if apierrors.hasstatuscause(err, v1.namespaceterminatingcause) {
// if the namespace is being terminated, we don't have to do
// anything because any creation will fail
return nil
}
}
return err
})
...
}
...
}
当 filteredpods 小于 replicaset 中 spec 域定义的 replicas 时,进入 rsc.podcontrol.createpods 创建 pod:
func (r realpodcontrol) createpods(ctx context.context, namespace string, template *v1.podtemplatespec, controllerobject runtime.object, controllerref *metav1.ownerreference) error {
return r.createpodswithgeneratename(ctx, namespace, template, controllerobject, controllerref, "")
}
func (r realpodcontrol) createpodswithgeneratename(ctx context.context, namespace string, template *v1.podtemplatespec, controllerobject runtime.object, controllerref *metav1.ownerreference, generatename string) error {
...
return r.createpods(ctx, namespace, pod, controllerobject)
}
func (r realpodcontrol) createpods(ctx context.context, namespace string, pod *v1.pod, object runtime.object) error {
...
newpod, err := r.kubeclient.corev1().pods(namespace).create(ctx, pod, metav1.createoptions{})
...
logger.v(4).info("controller created pod", "controller", accessor.getname(), "pod", klog.kobj(newpod))
...
return nil
}
接着,回到 replicasetcontroller.syncreplicaset:
func (rsc *replicasetcontroller) syncreplicaset(ctx context.context, key string) error {
...
newstatus := calculatestatus(rs, filteredpods, managereplicaserr)
updatedrs, err := updatereplicasetstatus(logger, rsc.kubeclient.appsv1().replicasets(rs.namespace), rs, newstatus)
if err != nil {
return err
}
...
}
虽然 pod 重建过,不过这里的 filteredpods 是 0,updatereplicasetstatus 会更新 replicaset 的当前状态为 0。
更新了 replicaset 的状态又会触发 replicaset 的 event handler,从而再次进入 replicasetcontroller.syncreplicaset。这时,如果 pod 重建完成,filteredpods 将过滤出重建的 pod,调用 updatereplicasetstatus 更新 replicaset 的当前状态到期望状态。
本文介绍了 kube-controller-manager 的运行流程,并且从一个删除 pod 的示例入手,看 kube-controller-manager 是如何控制资源状态的。
