目录
1.卡顿分析系统介绍
此系统拥有了端上采集两个维度数据的能力
- 方法运行数据:系统在编译期间基于asm9 agp7 自定义方法id映射 自定义字节码指令集实现了方法运行数据的采集。
- 帧性能数据:系统在运行期间基于framematrix 自定义数据结构体实现了端上帧数据的采集。
当app发生运行卡顿时,系统可自动分析堆栈,并且关联卡顿帧的方法调用链,并作出记录最终导出至文件。整体基于协程制作,性能损耗仅需1%。
基于compose kmp独创了多端可用的线下还原器,将采集到的数据做格式效验,并作出二次还原解析,进行了perfetto的二次开发,实现了可视化展示整体信息的能力。
2.思路介绍
2.1方法运行数据采集
2.1.1方法id映射
由于系统会在运行期间会采集大量数据,所以需要将庞大的方法名映射为指定id的能力,如下
//方法id`方法具体全路径和行参 24`com.d.hookplus.hookapplication$oncreate$1.onactivitysaveinstancestate[android.app.activity,android.os.bundle,]
此处的方法名包含了全路径和行参,如果通过字符串记录是十分庞大的,所以在编译期间使用asm技术将其对应成id,降低空间复杂度
2.2.2函数记录能力
在asm轮训期间,在方法开始和结束位置各插入对应的指令用于实现标记功能
override fun onmethodenter() {
//方法进入
methodvisitor?.perfettovisitmethoddelegate(perfettocentre.const.method_enter, methodid)
super.onmethodenter()
}
override fun onmethodexit(opcode: int) {
//方法退出
methodvisitor?.perfettovisitmethoddelegate(perfettocentre.const.method_exit, methodid)
super.onmethodexit(opcode)
}
处理退出指令时,catch和return指令也有对应的记录
在对应的时机插入对应的代码
this.let { methodvisitor ->
methodvisitor.visitfieldinsn(
getstatic,
"com/d/hookcore/perfetto/perfettocore",
"companion",
"lcom/d/hookcore/perfetto/perfettocore$companion;"
)
methodvisitor.visitintinsn(bipush, enterorexit)
methodvisitor.visitintinsn(sipush, methodid)
methodvisitor.visitmethodinsn(
invokevirtual,
"com/d/hookcore/perfetto/perfettocore$companion",
"gettraceline",
"(ii)v",
false
)
}
例:
private fun initrecycler() {
//方法开始,第一个参数用于标记进入或者退出,第二个参数用于标记映射的方法id
perfettocore.gettraceline(0,12)
var recyclerview: recyclerview = findviewbyid(r.id.rec)
recyclerview.adapter = nodeadapter(messagelist)
perfettocore.gettraceline(1,12)
}
- 插入完代码的例子如下:
2.2.3.运行方法记录内容
方法记录后的结果如下
如:main-1,942155.120954153,1,39,1
| 说明 | 例 |
|---|---|
| 当前线程 | main |
| 当前线程id | 1 |
| 当前时间秒值 | 942155.120954153 |
| 当前方法标记(进入或退出) | 1 |
| 当前方法id | 39 |
| 当前帧位下标 | 1 |
2.2帧数据采集
2.2.1于传统方式的区别
区别于choreographer hook的方式,系统采用了framematrix实现了帧数据采集
choreographer的hook点是在looper.loop之中的printer.println下,
final printer logging = me.mlogging;
if (logging != null) {
//hook点
logging.println(">>>>> dispatching to " msg.target " " msg.callback ": " msg.what);
}
缺点如下:
每次都需要字符串匹配,性能损耗严重
在api31之中被封掉了
2.2.2framematrix的能力
framematrix通过addonframemetricsavailablelistener实现了帧数据获取的能力
window.addonframemetricsavailablelistener({ window, framemetrics, dropcountsincelastinvocation ->
//do something
}, framemetricshandler)
如果不对window进行addonframemetricsavailablelistener,数据也会保留在平台层,所以没有性能损耗
framematrix是android平台层提供的帧数据采集,包含如下信息
| 类别 | 参数 | 说明 |
|---|---|---|
| 获取每帧性能数据 | first_draw_frame | 表示当前帧是否是当前 window 布局中绘制的第一帧 |
| intended_vsync_timestamp | 当前帧的预期开始时间, 如果此值与 vsync_timestamp 不同,则表示 ui 线程上发生了阻塞,阻止了 ui 线程及时响应vsync信号 | |
| total_duration | 表示此帧渲染并发布给显示子系统所花费的总时间, 等于所有其他具有时间价值的指标的值之和 | |
| vsync_timestamp | 在所有 vsync 监听器和帧绘制中使用的时间值(choreographer 的帧回调, 动画, view#getdrawingtime等) | |
| cpuduration | command_issue_duration | 表示向 gpu 发出绘制命令的耗时 |
| swap_buffers_duration | 表示将此帧的帧缓冲区发送给显示子系统所花的时间 | |
| uiduration | unknown_delay_duration | 表示等待 ui 线程响应并处理帧所经过的时间, 大多数情况下应为0 |
| input_handling_duration | 表示处理输入事件回调的耗时 | |
| animation_duration | 表示执行动画回调的耗时 | |
| layout_measure_duration | 表示对 view 树进行 measure 和 layout 所花的时间 | |
| draw_duration | 表示将 view 树转换为 displaylist 的耗时 | |
| sync_duration | 表示将 displaylist 与渲染线程同步所花的时间 |
2.3.同步算法
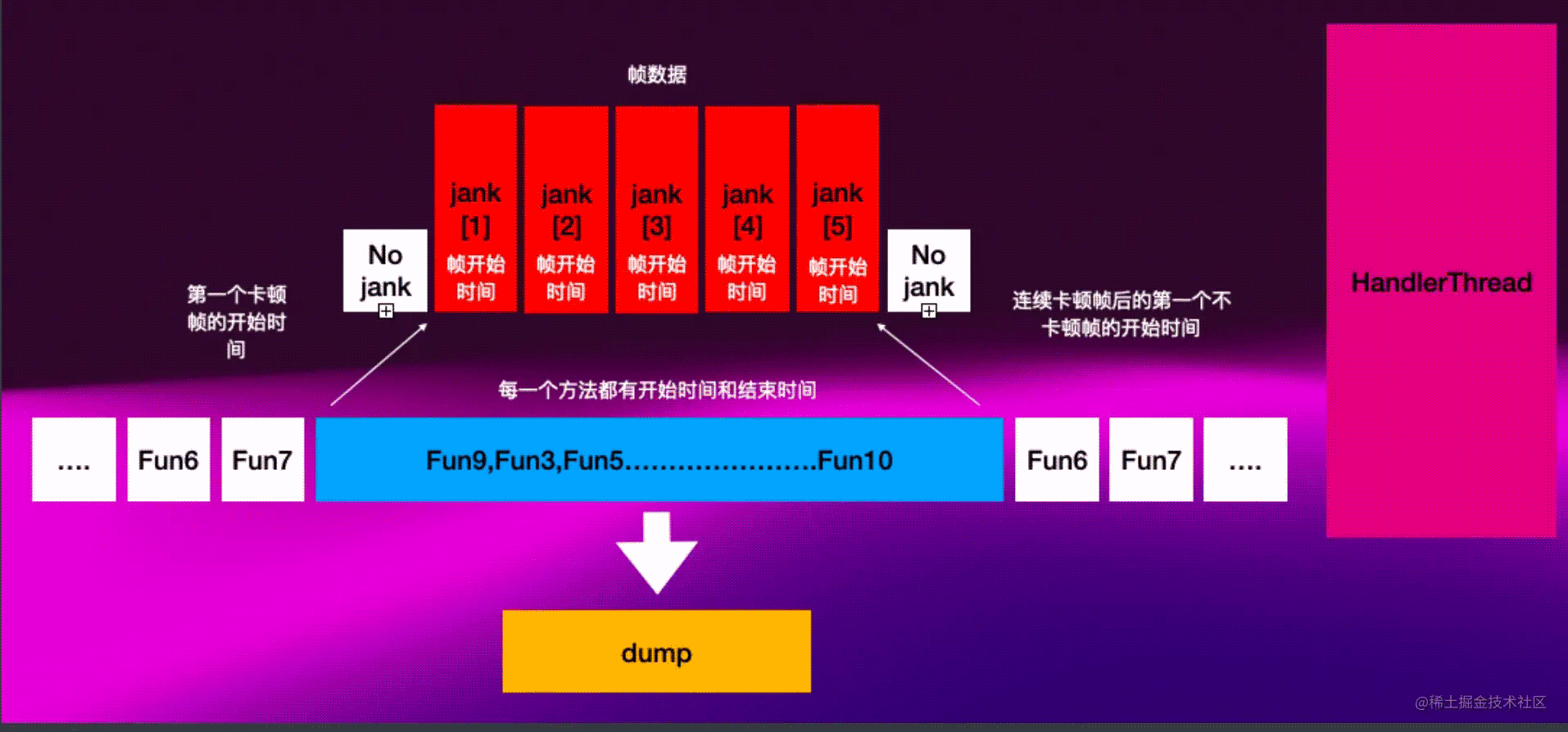
同步算法是将方法运行数据和帧性能数据自动分析,裁剪,合并出问题堆栈,并保存到指定位置的过程
在开发者自定义连续卡顿多少帧后进行dump
如果每卡顿一帧就dump,信息量太密集,并且意义不大,建议开发者连续卡顿5帧起步
2.3.1.同步算法细节
整个同步的过程是在单独的一个handlerthread中进行的,所以面临了两个难题:
由于handlerthread接受帧数据的时机是不确定的,即可能方法数据已经收集到很多帧以后了,但是帧数据才刚刚到来。如何精准定位到卡顿范围内的全部函数
如何尽可能减小性能损耗,降低时间复杂度和空间复杂度
所以我们整个同步的过程是围绕着这两个问题进行设计的
2.3.2.算法合并过程
如果卡顿帧连续个数到达了开发者定义的个数,那么开始还原
将首个卡顿帧的开始时间和连续卡顿帧后的第一个不卡顿帧的开始时间作为时间范围,与函数运行数据的时间点进行校准。匹配到函数运行的范围区域,并通过两个指针进行标记
具体匹配的过程是通过魔改版的二分查找实现
将标记出的函数运行范围进行导出
导出的能力是基于nio实现的
导出完毕后将函数指针位移到开始位置,重复利用空间
上述过程均在子线程进行,对主线程无影响,现阶段损耗为3%左右
2.4.可视化展示
- 将dump出的数据进行二次改造,支持可视化展示
2.4.1.线下还原器
- 基于perfetto的构造格式进行二次改造,用于支持可视化展示
2.4.2.支持多端的线下还原器
基于compose kmp实现了多端的可视化还原器,效果如下:
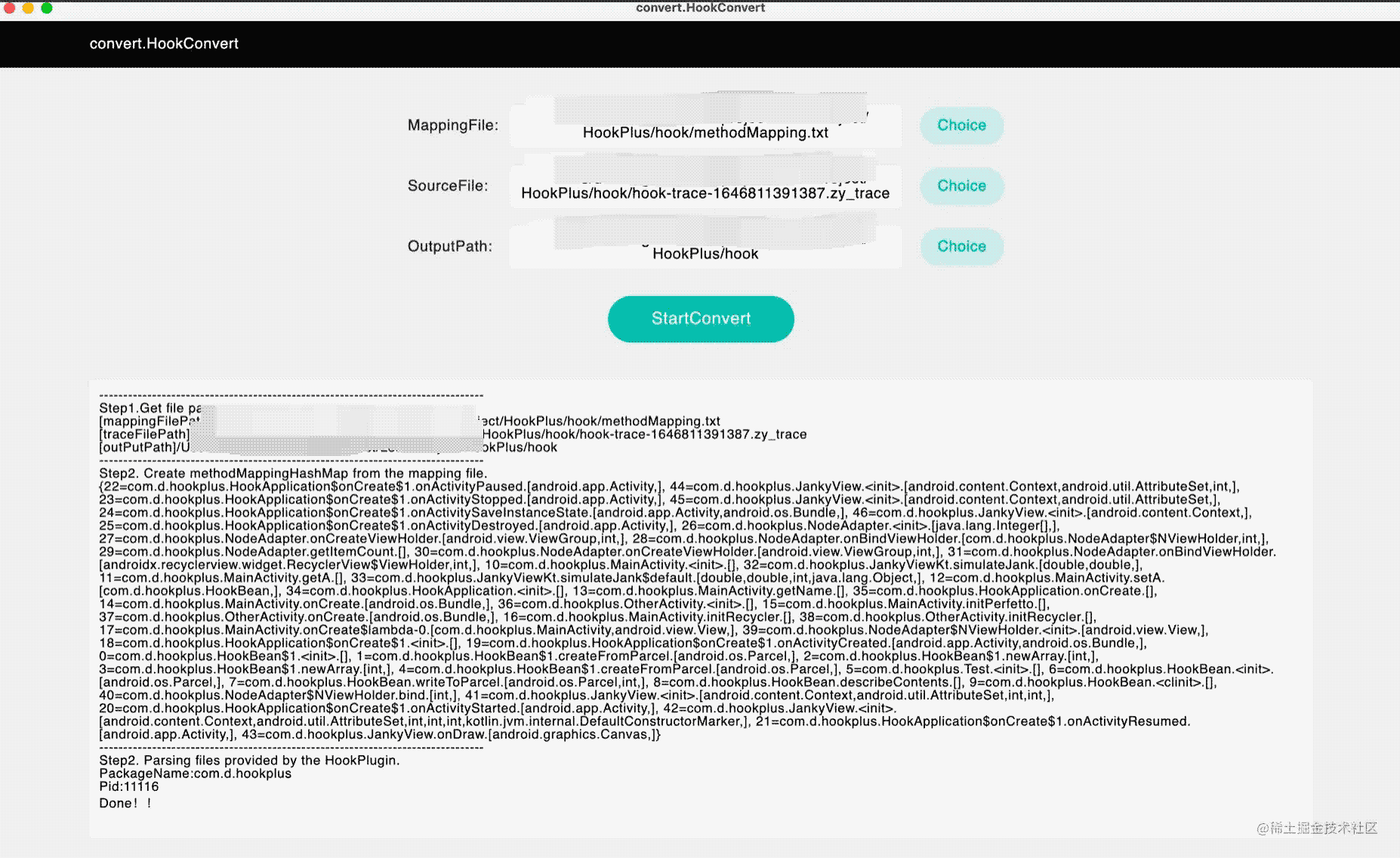
参数说明如下:
- mappingfile:函数id映射文件
- sourcefile:后缀为.zy_trace的文件,是系统自动采集的格式
- outputpath:输出为perfetto识别格式的文件目录
还原格式细节
如下:
com.d.hookplus|11116 main-1,942155.105176549,0,29,0 main-1,942155.105229674,1,29,0 main-1,942155.105313008,0,29,0 main-1,942155.105322383,1,29,0 main-1,942155.105492174,0,29,0 main-1,942155.105503112,1,29,0 main-1,942155.105524466,0,30,0 .......
# tracer: nop # # entries-in-buffer/entries-written: 30624/30624 #p:4 # # _-----=> irqs-off # / _----=> need-resched # | / _---=> hardirq/softirq # || / _--=> preempt-depth # ||| / delay # task-pid tgid cpu# |||| timestamp function # | | | | |||| | | com.d.hookplus-main-1 [000]... 942155.105177: tracing_mark_write: b|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105230: tracing_mark_write: e|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105313: tracing_mark_write: b|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105322: tracing_mark_write: e|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105492: tracing_mark_write: b|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105503: tracing_mark_write: e|11116|0com.d.hookplus.nodeadapter.getitemcount.[] com.d.hookplus-main-1 [000]... 942155.105524: tracing_mark_write: .....
- 改造前:
- 改造后:
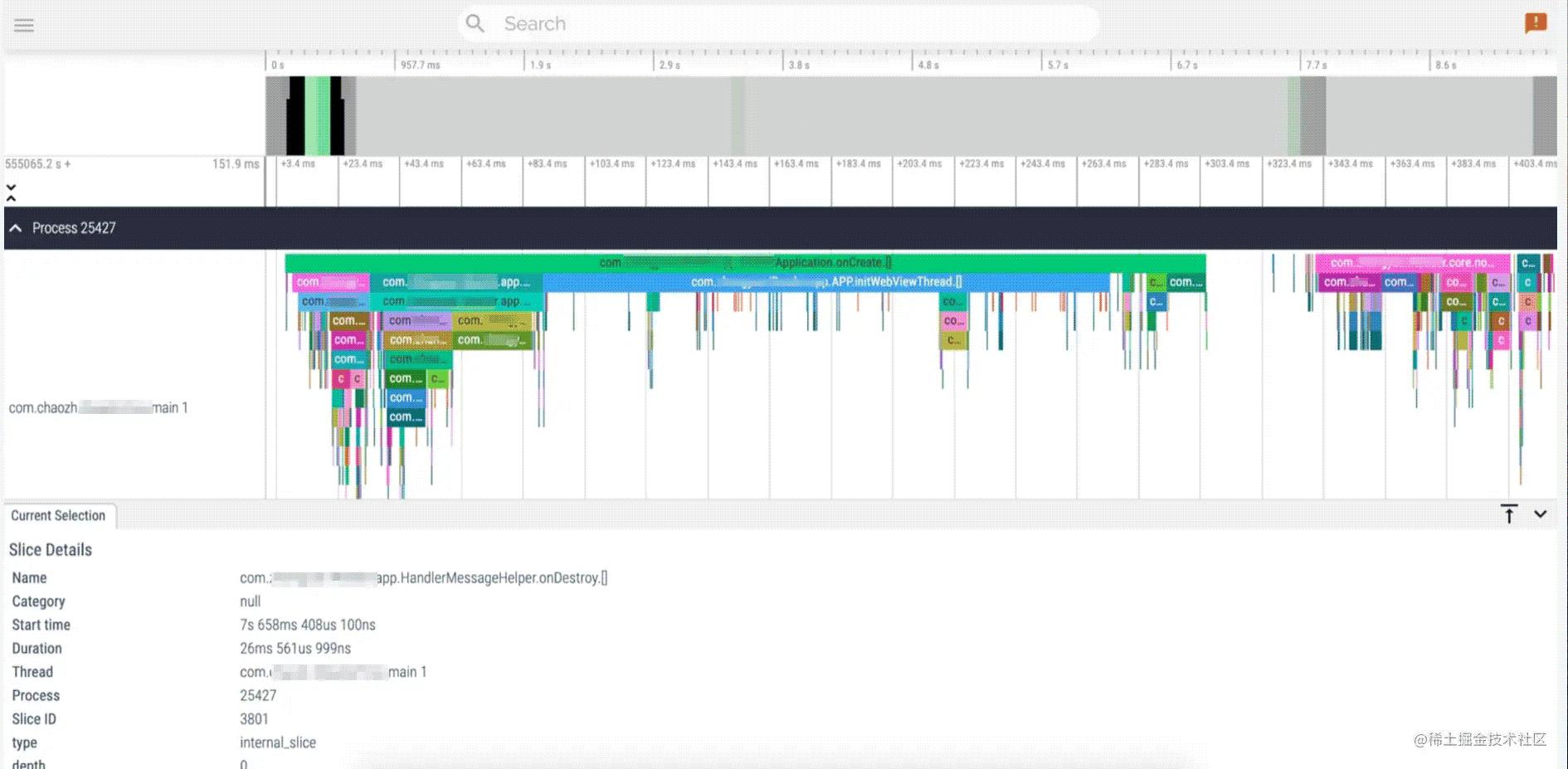
2.4.3.可视化展示
- 最终将还原器输出的文件直接导入至perfetto系统中,效果如下
以上就是jankman-极致的卡顿分析系统的详细内容,更多关于jankman卡顿分析系统的资料请关注其它相关文章!
