英特尔正式揭晓lunar lake客户端处理器的架构细节,如果用一句话来概括那就是——变化巨大,包括模块化结构、封装工艺、全新性能核与能效核、线程调度、gpu、npu以及连接等等。
这一系列的变化也带来了性能、能效、特性的全面提升。
根据英特尔公布的内容显示,lunar lake整体功耗相比上代下降40%;核显的游戏和图形性能提高1.5倍;全新npuai性能最高可达前代4倍,平台ai算力高达120tops。

接下来就为大家详细解读一下英特尔旨在进一步发力ai pc的lunar lake究竟有哪些不凡之处。
全新的模块化设计以及封装级内存
lunar lake延续了meteor lake的分离式模块设计,但从后者的“计算模块、soc模块、图形模块、io模块”四大模块简化为——计算模块(compute tile)、平台控制器模块(platform controller tile)两部分(在角落还有填料模块,但不具备电路和功能,只是为了保证结构整体强度),采用3d foveros封装工艺。

另一个重要变化在于英特尔首次将内存集成到封装内,称为“封装级内存(memory on package,mop)”,2颗内存容量最高32gb,支持lpddr5x,每个芯片最高8.5gt/s(8500mhz),支持4个16bit通道。

封装到soc内部缩短了内存走线,能够将物理功耗降低40%,并节省250平方毫米主板面积,对于内部空间紧凑的轻薄本而言,则留出了更多的设计空间。
只不过这也意味着搭载lunar lake的笔记本无法完成扩展和升级,在购买时建议有较大内存需求的用户“一步到位”,毕竟无论是影像创作、本地化ai或者多任务处理,对于内存的需求正快速提升。
再来看lunar lake的两大全新模块。
计算模块:混合架构最多具备4个性能核、4个能效核,还包括gpu核显、npu、媒体引擎、显示引擎、ipu图像处理单元、noc、msc(内存侧缓存)。msc最大容量8mb,独立于二三级缓存,主要用于io引擎的缓存配合,可以减少对系统内存的依赖,提升延迟与带宽。
计算模块相比上代还有一个重要变化在于采用了全新低功耗岛(low power island),将所有节能模块统一管理,提升能效。
平台控制模块:包含pcie 5.0/4.0控制器、雷电4控制器、usb控制器、wi-fi与蓝牙控制器、安全引擎等。
lunar lake提供最多4条pcie 5.0、4条pcie 4.0总线通道;支持wi-fi 7(5g gig),最高速率达5.8gbps,支持蓝牙5.4;这一次还是没有雷电5,支持的雷电4带宽40gbps,最多三个连接,而且支持新的雷电共享技术,实现不同pc之间快捷分享、传输与控制。

计算模块与平台控制模块通过可扩展第二代交叉总线以及d2d界面互联。另外lunar lake还集成4个电源控制器,可实现增强遥测,可动态调节电压。
同时为了优化能效,lunar lake的电源管理架构也有了变化,在独立pmic、增强的英特尔线程控制器、内存侧缓存与改进的处理器核心,共同实现了功耗节省。

至于lunar lake采用的制程工艺,英特尔尚未公布。
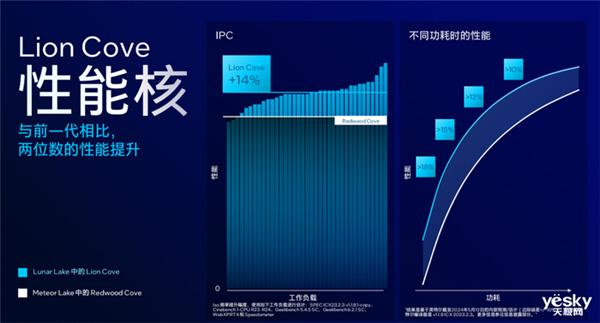
lion cove性能核——p核
lunar lake的性能核代号lion cove,采用了全新微架构,相比前代大幅提升了ipc并增强了可扩展性;优化了单线程每瓦性能以及单位面积性能。

lion cove的每个核心一级数据缓存48kb,一级指令缓存192kb,二级缓存最多2.5mb,所有核心共享最多12mb三级缓存。
另外,该性能核拥有18个执行端口,预测宽度提升8倍;支持更精准的频率控制,间隔缩小到16.67mhz,更灵活把控能效。
根据英特尔公布的数据,lunar lake对比meteor lake性能核ipc平均提升约14%,而且lunar lake在越低功耗下的表现优势越明显。
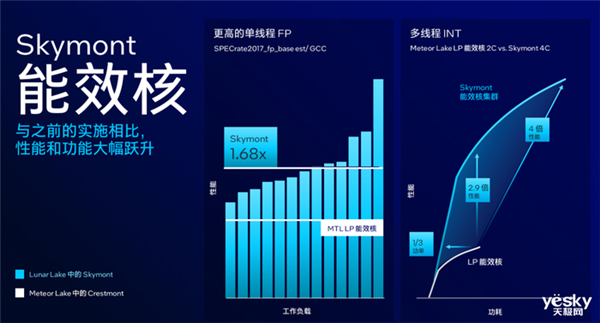
skymont能效核——e核
lunar lake全新能效核代号skymont,英特尔表示希望能效核可以覆盖更多日常算力要求,因此lunar lake的能效核skymont设计是按照raptor lake性能核匹配的,并且保持能效核在节能方面的优势。
基于此,skymont能够支持更多应用场景、提升了多线程性能以及扩展性,同时拥有2倍的矢量和ai吞吐量以更好地支持vnni功能。

skymont能效核拥有26个调度端口,更深的队列提升并行处理能力,还具备更宽的分配和回退。
lunar lake能效核每个核心拥有32kb一级数据缓存,所有核心共享4mb的二级缓存(l2缓存带宽翻倍),没有三级缓存。
性能方面,英特尔表示4个能效核组成一个集群,相比meteor lake同等性能功耗仅为三分之一,同功耗下性能提升可达到2.9倍,最高性能达到了后者的4倍。
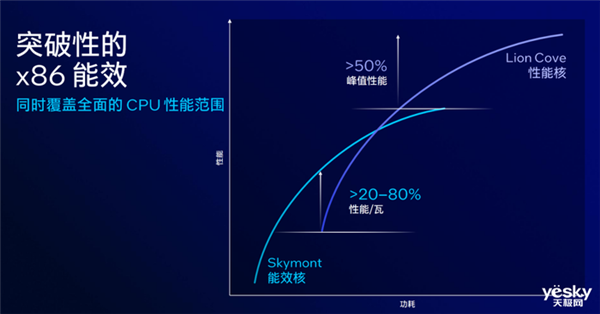
因此,全新架构的性能核、能效核,为英特尔新一代x86处理器带来了更强的性能以及更高能效。
其中性能核的峰值性能对比能效核提升50%,二能效核的每瓦性能优势在20%到80%。由此,lunar lake能够针对复杂多样化场景,实现灵活调度,保障续航。
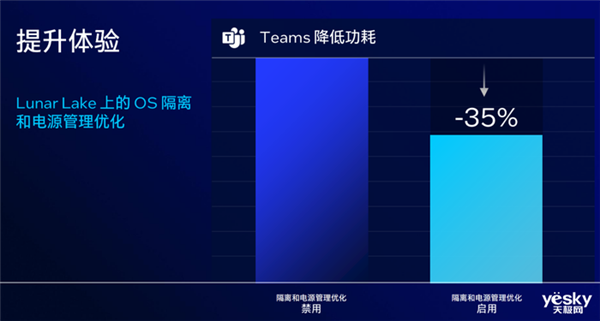
持续增强的英特尔硬件线程调度器
英特尔硬件线程调度器在lunar lake中也有提升,带来了动态调度策略、增强算法、更精细的控制,让oem也有更大的定制范围。同时配合上操作系统隔离区、加强电源管理等设计,也可以保证能效,英特尔表示在teams应用中,启用这些功能后,功耗可以降低35%。


而且在性能核与能效核的调度方面,英特尔硬件线程调度器也会充分考虑能效,如工作负载合适将优先分配给单能效核,多线程时进行能效核扩展,后根据需求引导至性能核。

升级xe2微架构的gpu
上代meteor lake引入锐炫gpu后,翻倍的核显性能让人印象深刻,这一次lunar lake的gou也升级到第二代xe2微架构,性能约为前代的1.5倍。
具体来看,xe2 gpu算力可达67tops——拥有8个第二代xe核心,采用全新xmx引擎(int 8整数操作每秒4096和fp 16浮点操作每秒2048)、可配备8个更强的光追单元、增强的xess内核、xe2矢量引擎(优化能效和ai性能)、英特尔arc软件堆栈,拥有8mb二级缓存。
lunar lake还拥有全新媒体引擎,支持av1硬件编解码、h.266/vvc视频硬解码。vvc的优势在于降低比特率并保持同等画质,从而减少文件大小和传输压力,可自适应分辨率码率,更加灵活,还支持屏幕内容编码流(scc)、360度全景码流。

全新显示引擎可支持hdmi 2.1、dp 2.1、edp 1.5,可拓展最多三个屏幕,其中edp 1.5能够让笔记本屏幕提升自适应刷新、结合panel replay技术实现显示自适应同步等功能。
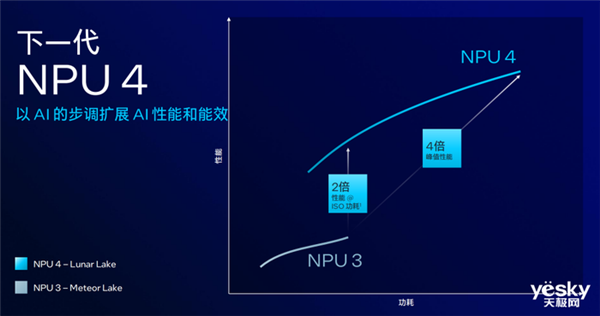
全新npu:4倍峰值性能
作为ai pc的“核芯”怎么会少得了npu?去年的meteor lake首次集成npu,作为新一代npu却并非“2.0”,按照英特尔技术迭代已经是“4.0”。
npu 4的架构增加了npu大小,更好地执行下一代ai工作负载;提升了时钟频率、能效,从而满足性能需求的同时延长续航;针对现代ai进行了优化,可以高效运行大语言模型以及transformer。
英特尔表示lunar lake的npu 4是面向ai pc“最大的集成和专用ai加速器”,拥有12个增强的shave dsp、6个神经计算引擎、能效优化的mac阵列、2倍带宽、支持原生激活功能和数据转换、用于大语言模型的嵌入标记化,以及48tops的算力。

对比meteor lake的npu 3,npu 4拥有其4倍的峰值性能。
当然,lunar lake的ai性能仍旧是cpu、gpu、npu聚合的多元算力,匹配复杂多样的ai负载,可兼顾能效。而且得益于每个计算单元性能大幅升级,lunar lake的平台算力达到了120tops,无论是游戏、创作中的ai需求,还是专用的ai助手,又或是轻量型ai负载,都能够更灵活高效应对。

写在最后
英特尔表示,lunar lake已经量产,将在第三季度正式发布上市,为超过20家oem的80多款ai pc提供动力。
另外,截至目前,英特尔已交付800万片酷睿ultra处理器,且英特尔预计在今年交付超过4000万片英特尔酷睿ultra处理器。
需要指出的是lunar lake还只是第二代酷睿ultra的成员之一,重点面向低功耗移动平台,在今年晚些时候还将有更高性能的arrow lake。
据悉,arrow lake同样基于lion cove、skymont混合架构,并首次采用intel 20a制程工艺。

相比前两年,今年的computex在ai pc的引导下明显热闹很多,英特尔、amd、高通等巨头之间的火药味也浓厚了几分(还有苹果虽然要晚几天,但wwdc应该也少不了ai的身影)。
当然了,各家计算平台还只是角逐ai pc头把交椅的筹码之一,生态合作、软件及工具支持、人才投入培养等方面同样关键。
特别是在ai pc发展早期,谁能在市场中站稳脚跟,真正实现ai pc的规模化应用,那么也将在未来的竞争中占据先手。
所以,今年下半年和明年陆续上市的ai pc产品,或许会呈现一种“百家争鸣”的局面,这既是芯片厂商的较量,也是oem之间的角逐,甚至是x86与arm两大核心阵营又一轮正面硬碰。
pc市场终于又变得有趣起来了,谁能成为ai pc时代的引领者,就让我们拭目以待吧。
