传统应用开发中,为了提升系统的查询性能,往往会在系统架构设计中加入缓存机制。在ai大模型领域,虽然功能非常强大,但是使用成本也是非常昂贵的,比如openai的gpt-4按照token的个数来计算费用。那么,在这种情况下是否有一种方案来解决呢?既能降低使用llm api的成本,也能同时提升调用llm api的效率和性能。gptcache的出现,专门解决了这类痛点,对于大语言模型的对话场景,没有必要每次都去调用llm的api,完全可以通过缓存调用一次即可,大大节省使用成本。本篇博客,笔者将为大家介绍gptcache的相关内容。
gptcache 是一款高效的开源缓存kb88凯时官网登录的解决方案,专为提升基于 gpt 的应用程序性能而设计。它通过语义缓存技术,有效存储语言模型的生成响应,从而加速应用程序的响应速度和整体效率。作为一个灵活的 llm 缓存层,gptcache 提供了高度可定制的缓存选项,允许用户根据特定需求调整嵌入函数、相似性评估机制、数据存储位置以及缓存驱逐策略。目前,gptcache 支持与 openai chatgpt 和 langchain 接口的集成,扩展了其在多种应用场景下的适用性。
2.1 为什么使用 gptcache?
使用语义缓存来存储 llm 响应的好处如下:
-
提升性能:将 llm 响应存储在缓存中可以显著减少检索响应所需的时间。如果之前的请求已经存储在缓存中,能够更大幅度地降低响应时间,提高应用程序的整体性能;
- 节省开销:大多数llm服务根据请求次数和 的组合收费。缓存 llm 响应可以减少对服务 api 的调用次数,从而节省成本。尤其是在高流量场景下,缓存尤为重要。如果不使用语义缓存,可能会多次调用 api,产生极高的费用;
-
提高可扩展性:缓存 llm 响应可以通过降低 llm 服务的负载来提高整体应用的可扩展性。语义缓存有助于避免系统瓶颈,确保应用可以处理更多请求;
- 降低开发成:语义缓存工具能够减少大语言模型应用的开发成本。开发过程中需要连接大语言模型的 api,因此成本可能会十分高昂。gptcache 界面与大语言模型 api 相同,可存储模型生成数据。使用 gptcache 无需再连接至大语言模型 api,从而降低成本;
- 降低网络延迟:语义缓存更靠近客户端,可以减少从 llm 服务检索数据所需的时间。降低网络延迟能有效提升用户的整体体验;
- 提升可用性:llm 服务频繁限制用户或客户端在特定时间段内访问的频次。触达访问速率上限时,请求会被屏蔽。用户不得不等待一段时间后才可以继续访问服务器,这种限制会导致服务中断。使用 gptcache 后,您可以根据应用用户数量和查询量灵活快速扩展,保障服务可用性和性能。
总的来说,开发用于存储llm响应的语义缓存可以提供多种好处,包括性能改进、降低成本、更好的可伸缩性、自定义性和降低网络延迟。
2.2 gptcache 的工作原理
gptcache 通过捕捉在线服务数据的局部性特征,对频繁使用的数据进行存储,从而显著减少检索延迟并缓解后端服务器的压力。区别于传统的缓存kb88凯时官网登录的解决方案,gptcache 实现了先进的语义缓存机制,能够识别并保留高度相似或紧密相关的查询,大幅提升缓存的命中率。
该工具运用 embedding 技术将用户的问题转换为向量形式,并借助向量数据库执行相似性查询,以便从缓存中快速提取相关响应。gptcache 的模块化架构设计为用户提供了极大的灵活性,使得每个组件都可以根据用户的具体需求进行个性化配置。
尽管语义缓存在某些情况下可能会产生误报(false positives)或漏报(false negatives),gptcache 设计了三种性能评估指标,协助开发者对缓存系统进行细致的调优。
通过这一高效流程,gptcache 能够有效地在缓存中定位并提取出与用户查询相似或相关的信息,如流程图所示:
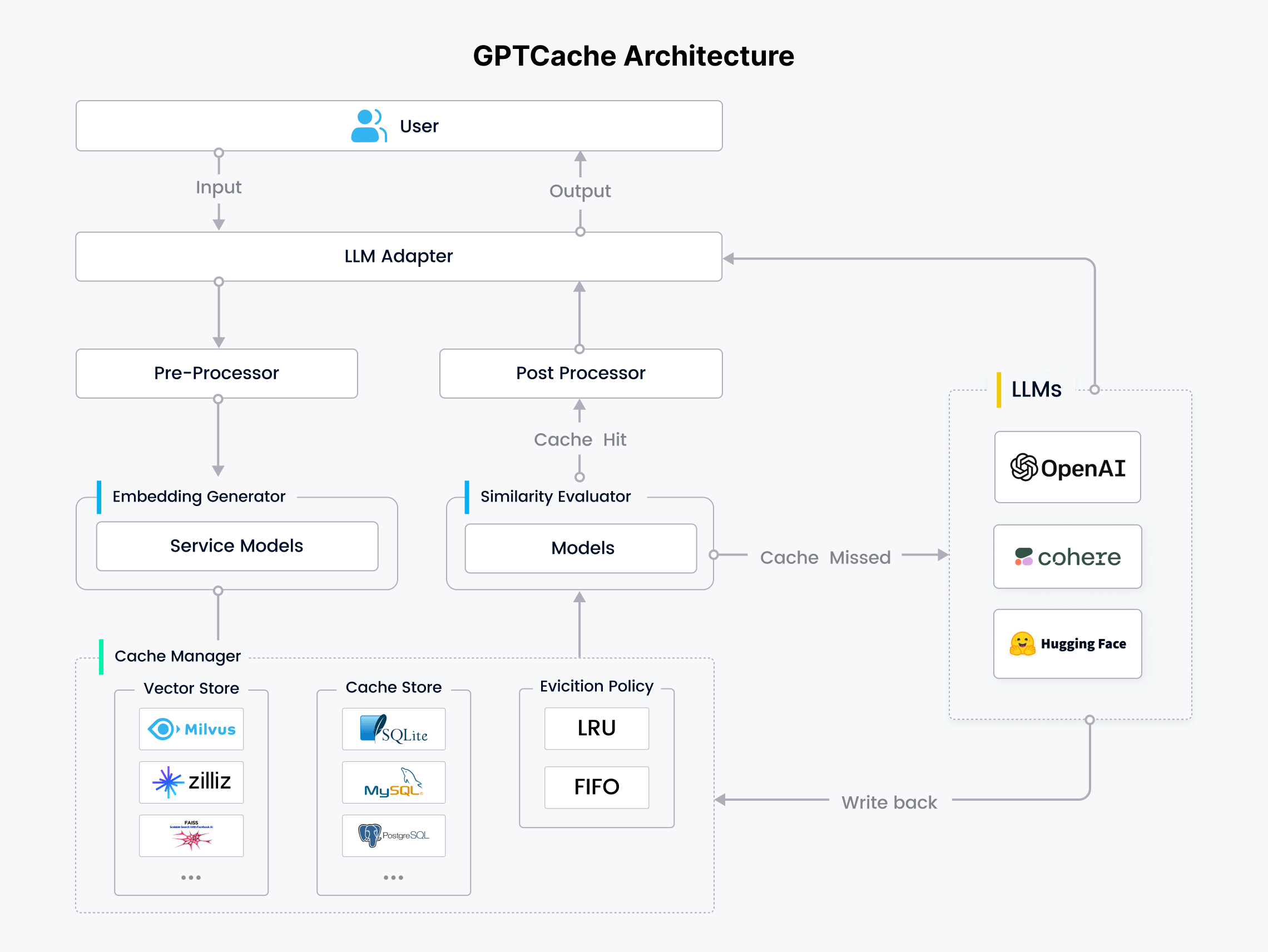
2.3 什么是语义缓存
gptcache 的模块化架构提供了灵活性和可定制性,使用户能够根据特定的应用需求和场景,轻松构建和调整个性化的语义缓存kb88凯时官网登录的解决方案。每个组件都配备了多样的配置选项,确保用户能够精准地实现其缓存策略,以适应不同的业务挑战和技术环境。
1.大语言模型适配器(llm adapter)
适配器将大语言模型请求转换为缓存协议,并将缓存结果转换为 llm 响应。适配器方便轻松集成所有大语言模型,并可灵活扩展。gptcache 支持多种大语言模型,包括:
- openai chatgpt api
- langchain
- minigpt4
- llamacpp
- dolly
- 后续将支持:hugging face hub、bard、anthropic 等
2.预处理器(pre-processor)
预处理器管理、分析请求,并在将请求发送至 llm 前调整请求格式,具体包括:移除输入种冗余的信息、压缩输入信息、切分长文本、执行其他相关任务等。
3.向量生成器(embedding generator)
embedding 生成器将用户查询的问题转化为 embedding 向量,便于后续的向量相似性检索。gptcache 支持多种模型,包括:
- openai embedding api
- onnx(gptcache/paraphrase-albert-onnx 模型)
- hugging face embedding api
- cohere embedding api
- fasttext embedding api
- sentencetransformers embedding api
- timm 模型库中的图像模型
4.缓存存储(cache store)
gptcache 将 llm 响应存储在各种数据库管理系统中。gptcache 支持丰富的缓存存储数据库,用户可根据性能、可扩展性需求和成本预算,灵活选择最适合的数据库。gptcache 支持多个热门数据库,包括:
5.向量存储(vector store)
向量存储模块会根据输入请求的 embedding 查找 top-k 最相似的请求。简而言之,该模块用于评估请求之间的相似性。gptcache 的界面十分友好,提供丰富的向量存储数据库。选择不同的向量数据库会影响相似性检索的效率和准确性。gptcache 支持多个向量数据库,包括:
- milvus
- zilliz cloud
- milvus lite
- hnswlib
- pgvector
- chroma
- docarray
- faiss
6.逐出策略(eviction policy)
管理:控制缓存存储和向量存储模块的操作。缓存满了之后,缓存替换机制会决定淘汰哪些数据,为新数据腾出空间。gptcache 目前支持以下两种标准逐出策略:
- “最近最少使用”逐出策略(least recently used,lru)
-
“先进先出”逐出策略(first in first out,fifo)
7.相似性评估器(similarity evaluator)
gptcache 中的相似性评估模块从 cache storage 和 vector store 中收集数据,并使用各种策略来确定输入请求与来自 vector store 的请求之间的相似性。该模块用于确定某一请求是否与缓存匹配。gptcache 提供标准化接口,集成各种相似性计算方式。多样的的相似性计算方式能狗灵活满足不同的需求和应用场景。gptcache 根据其他用例和需求提供灵活性。
8.后处理器(post-processor)
后处理器负责在返回响应前处理最终响应。如果没有命中缓存中存储的数据,大语言模型适配器会从 llm 请求响应并将响应写入缓存存储中。
接下来,笔者将介绍学习如何有效地使用 gpt 聊天功能。虽然原始示例基于 openai 的演示,但我们的重点是教授如何通过 gptcache 来缓存精确和相似的响应,这一过程异常简洁。您只需遵循几个简单的初始化缓存的步骤即可。
在开始之前,请确保您已经通过设置环境变量 openai_api_key 来配置您的 openai api 密钥。如果您还未进行设置,根据您的操作系统(macos/linux或 windows),可以通过以下命令进行设置:
对于 macos/linux 系统:
export openai_api_key=your_api_key
完成这些步骤后,您可以通过以下代码示例来体验 gptcache 的应用和加速效果。我们将展示三个部分:使用 openai 的原始方式、进行精确搜索以及执行相似搜索。
1.使用 openai 的原始方式
实现代码如下所示:
import time from openai import chatcompletion def format_response(openai_response): return openai_response['choices'][0]['message']['content'] # 定义问题 question = 'what’s github' # 使用 openai api 获取响应 start_time = time.time() response = chatcompletion.create( model='gpt-4-0125-preview', messages=[{'role': 'user', 'content': question}] ) # 打印问题和响应 print(f"question: {question}") print(f"time consuming: {time.time() - start_time:.2f}s") print(f"answer: {format_response(response)}\n")
2.精确搜索
为了启动 gptcache 并优化性能,您需要进行适当的初始化。这包括从 gptcache.adapter 导入 openai 模块,这样会自动配置数据管理器以便于精确地匹配和检索缓存数据。有关如何构建和定制您自己的缓存系统的更多信息,请参考 gptcache 的构建指南。
当您向 chatgpt 提出两个完全相同的问题时,gptcache 将确保第二个问题的答案直接从缓存中获取,避免了对 chatgpt 的重复请求,从而提高了响应速度和效率。实现代码如下所示:
import time from gptcache import cache from gptcache.adapter import openai # 初始化 gptcache cache.init() cache.set_openai_key() def get_response_text(response): return response['choices'][0]['message']['content'] print("cache loading.....") question = "what's github" for _ in range(2): start_time = time.time() response = openai.chatcompletion.create( model='gpt-4-0125-preview', messages=[ {'role': 'user', 'content': question} ] ) print(f'question: {question}') print(f"time consuming: {time.time() - start_time:.2f}s") print(f'answer: {get_response_text(response)}\n')
3.相似搜索
为了配置 gptcache 以提高效率和性能,您需要定义几个关键组件:embedding_func 用于生成文本的嵌入表示,data_manager 负责管理缓存中的数据,以及 similarity_evaluation 用于评估不同文本之间的相似性。这些组件的具体设置和优化方法,详见“构建您的缓存”部分的详细指南。
当您使用 chatgpt 回答一系列相关的问题后,gptcache 能够根据之前的交互从缓存中提取答案,这样对于后续的相似问题,就无需再次向 chatgpt 发起请求,从而减少了延迟并提高了响应速度。实现代码如下所示:
import time from gptcache import cache, get_data_manager from gptcache.adapter import openai from gptcache.embedding import onnx from gptcache.similarity_evaluation.distance import searchdistanceevaluation from gptcache.manager import cachebase, vectorbase # 初始化 gptcache onnx = onnx() data_manager = get_data_manager(cachebase("sqlite"), vectorbase("faiss", dimension=onnx.dimension)) cache.init( embedding_func=onnx.to_embeddings, data_manager=data_manager, similarity_evaluation=searchdistanceevaluation() ) cache.set_openai_key() def get_response_text(response): return response['choices'][0]['message']['content'] print("cache loading.....") questions = [ "what's github", "can you explain what github is", "can you tell me more about github", "what is the purpose of github" ] for question in questions: start_time = time.time() response = openai.chatcompletion.create( model='gpt-4-0125-preview', messages=[{'role': 'user', 'content': question}] ) print(f'question: {question}') print(f"time consuming: {time.time() - start_time:.2f}s") print(f'answer: {get_response_text(response)}\n')
gptcache 目前具备了构建服务器的能力,该服务器不仅支持缓存功能,还能进行对话交互。通过简单的几行代码,用户便能够启动一个个性化的 gptcache 服务实例。以下是一个简洁的示例,演示了如何搭建 gptcache 服务器以及如何与其进行交互操作。
# 安装和启动服务 $ gptcache_server -s 127.0.0.1 -p 8000 # 用doker启动服务 $ docker pull zilliz/gptcache:latest $ docker run -p 8000:8000 -it zilliz/gptcache:latest
1.命令行交互
# 写数据到 gptcache curl -x 'post' \ 'http://localhost:8000/put' \ -h 'accept: application/json' \ -h 'content-type: application/json' \ -d '{ "prompt": "hi", "answer": "hi welcome" }'
# 从 gptcache 中读数据 curl -x 'post' \ 'http://localhost:8000/get' \ -h 'accept: application/json' \ -h 'content-type: application/json' \ -d '{ "prompt": "hi" }'
2.python实现
>>> from gptcache.client import client >>> client = client(uri="http://localhost:8000") >>> client.put("hi", "hi welcome") 200 >>> client.get("hi") 'hi welcome'
gptcache 是一个为基于 gpt 的应用程序设计的高性能缓存kb88凯时官网登录的解决方案,它利用语义缓存技术来存储和快速检索语言模型的输出。通过模块化设计,gptcache 支持个性化配置,允许用户根据需求选择嵌入函数、相似性评估方法和数据存储选项。它不仅提高了响应速度,减少了对原始数据源的请求,还通过智能缓存机制优化了服务器负载。此外,gptcache 支持构建对话服务器,简化了与大型语言模型的集成和交互,为用户提供了更加流畅和智能的体验。
