使用ollama anythingllm快速且简单的在本地部署llama3
不多说,直接开始
一、安装ollama
ollamad88尊龙官网手机app官网:
下载地址:
打开以后注册并下载即可
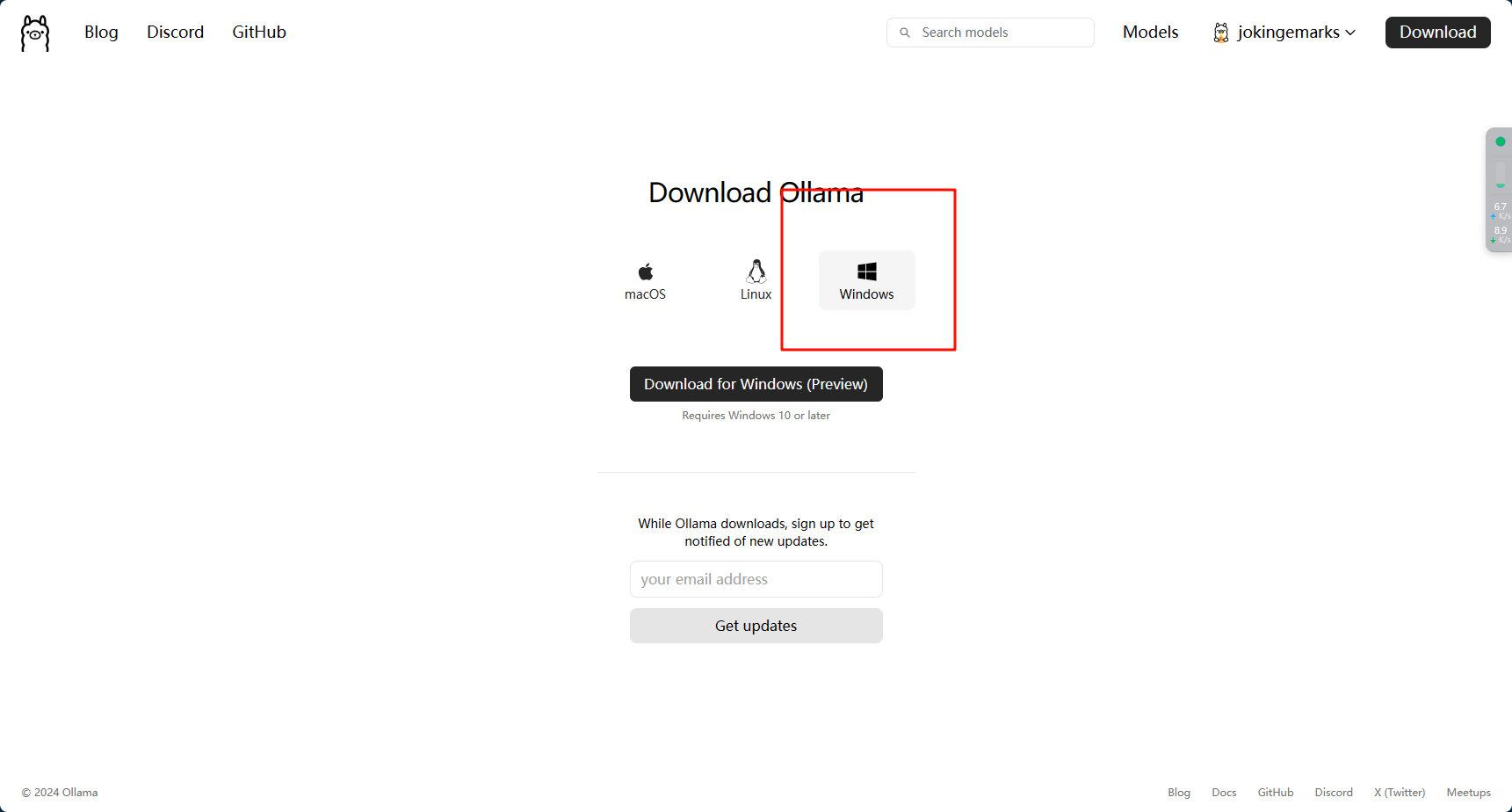
安装没有什么好说的,找到自己的系统安装即可,因为我的电脑没有搞虚拟机,所以就直接安装windows的版本了
二、下载模型并运行ollama
安装ollama以后,通过管理员打开powershell
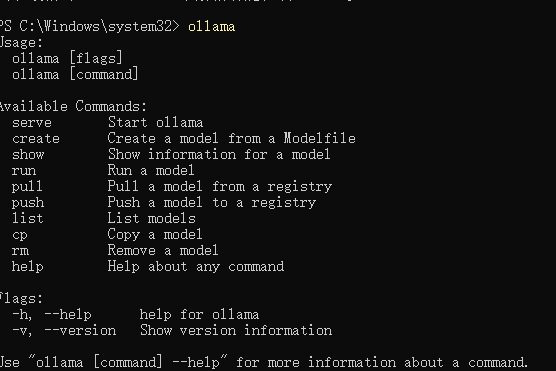
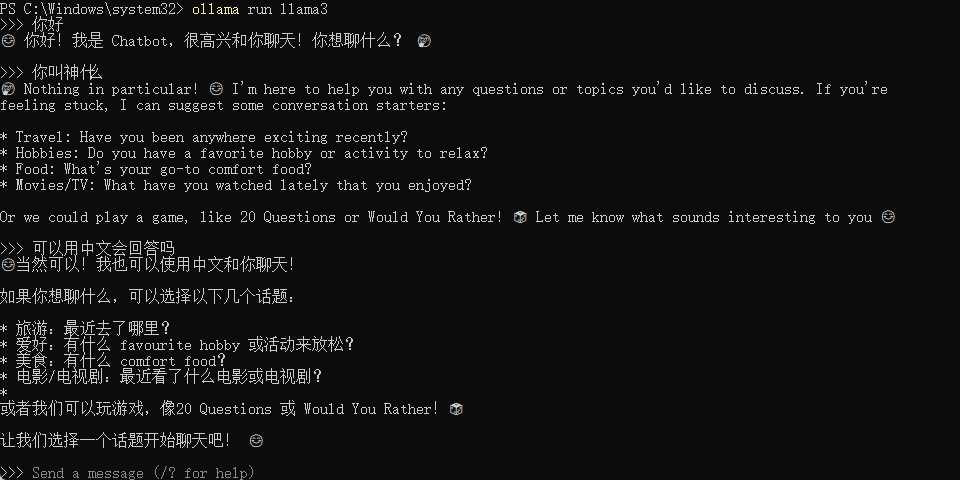
输入ollama,只要出现下面这些,说明安装成功了
打开ollama的模型的网页:
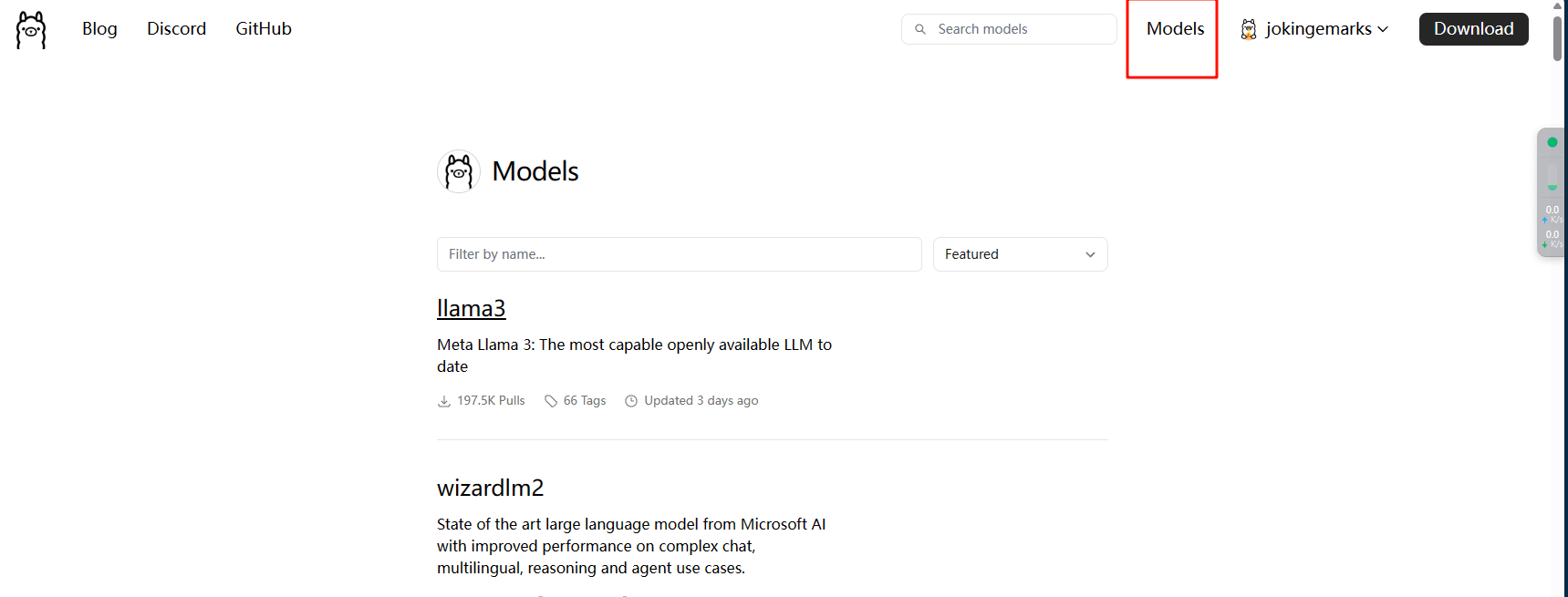
我们以llm3为例,双击进入
常用的命令有
serve start ollama
create create a model from a modelfile
show show information for a model
run run a model
pull pull a model from a registry
push push a model to a registry
list list models
cp copy a model
rm remove a model
help help about any command
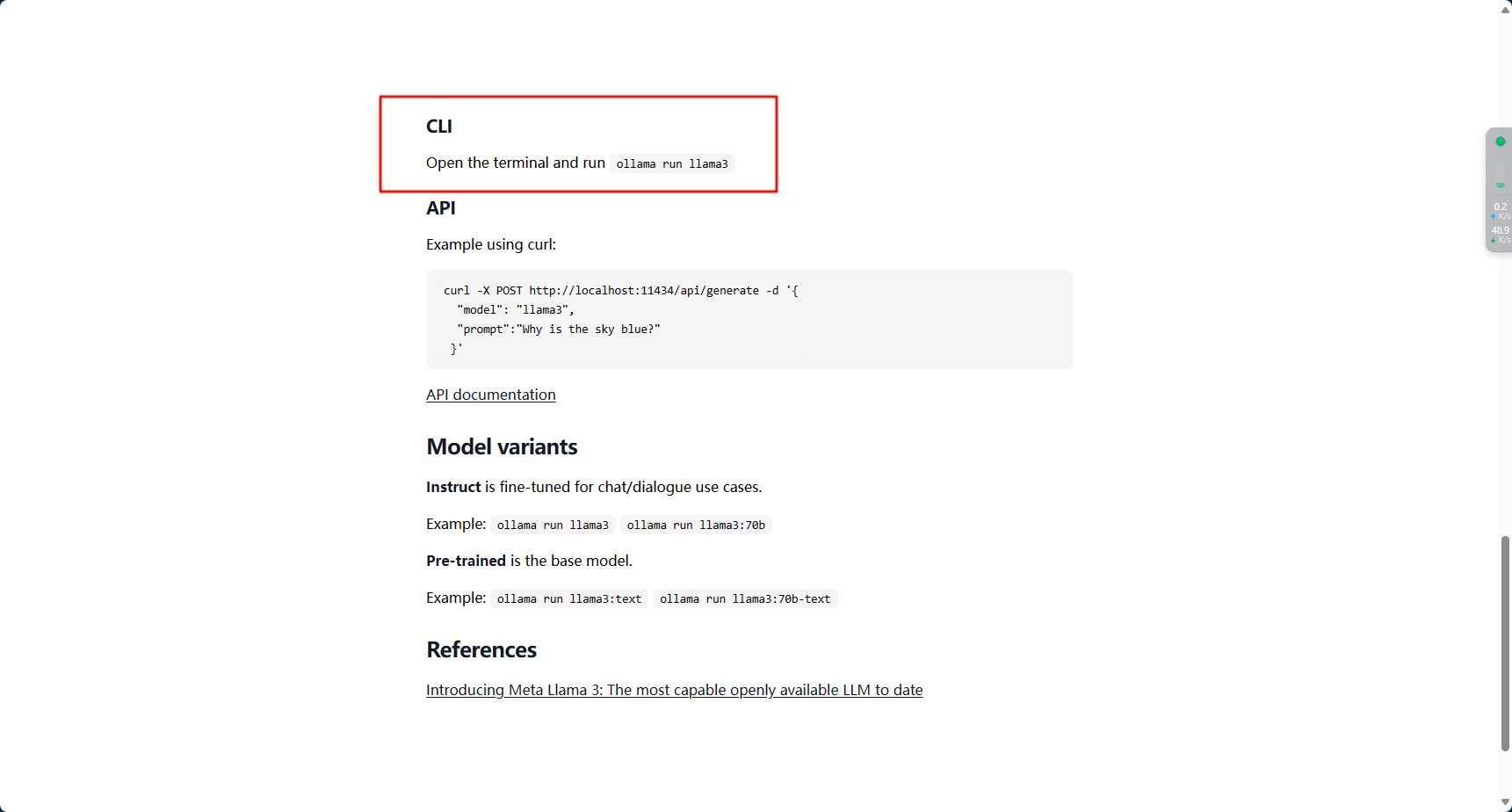
可以看到页面中让执行ollama run llama3即可
一般来说run是用来跑模型的,但是如果本地没有这个模型的话,ollama会自动下载
ps:国内的网络问题不知道有没有解决,下载模型的时候偶尔速度很快,但是很多时候速度很慢以至于提示tls handshake timeout,这种情况建议重启电脑或者把ollama重启一下(不知道为啥,我同步打开github的时候速度会明显快一些,可能也是错觉)
下载完成以后我们输入ollama list可以查下载了哪些模型

这里我们直接输入ollama run llama3,就可以开始对话了
三、下载并配置angthingllm
angthingllmd88尊龙官网手机app官网:
下载链接:
同样的选择对应的系统版本即可
在使用前,需要启动ollama服务
执行ollama serve,ollama默认地址为:
然后双击打开angthingllm
因为我已经配置过,所以不好截图最开始的配置界面了,不过都能在设置里面找到
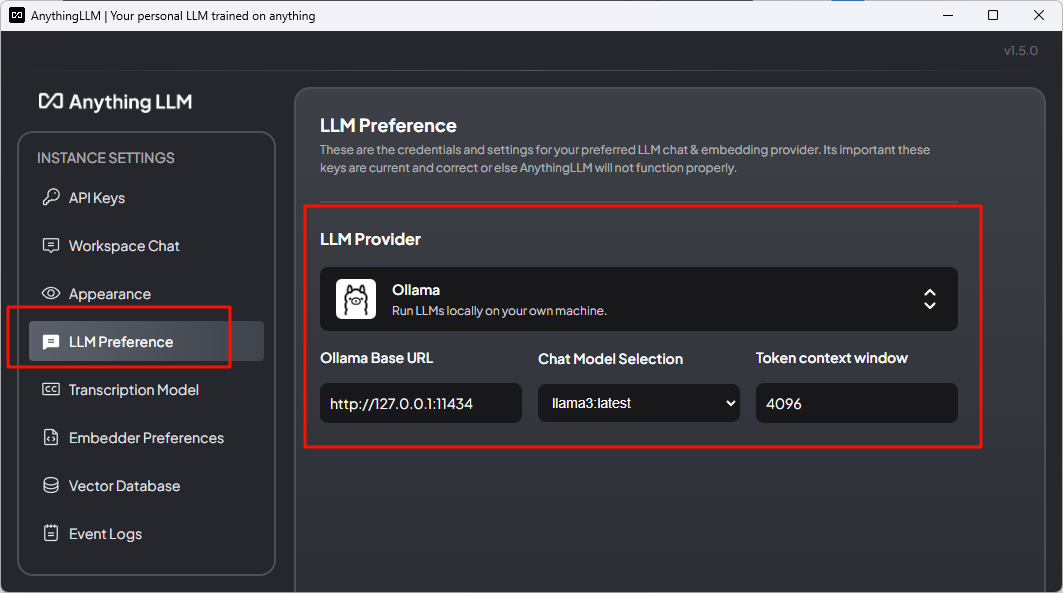
首先是llm preference,llm provider选择ollama,url填写默认地址,后面的模型选择llama3,token填4096
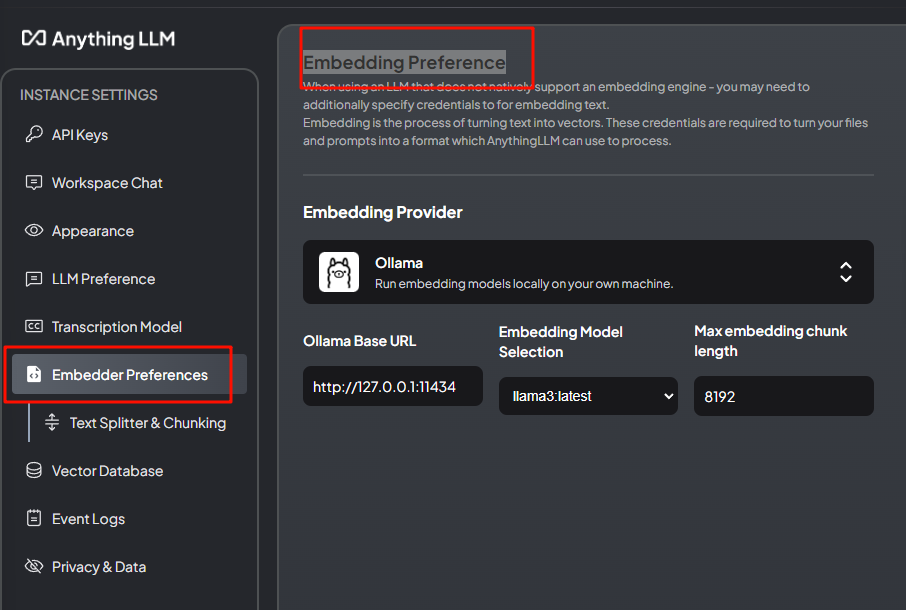
embedding preferenc同样选择ollama,其余基本一致,max我看默认8192,我也填了8192
vector database就直接默认的lancedb即可
此时我们新建工作区,名字就随便取,在右边就会有对话界面出现了
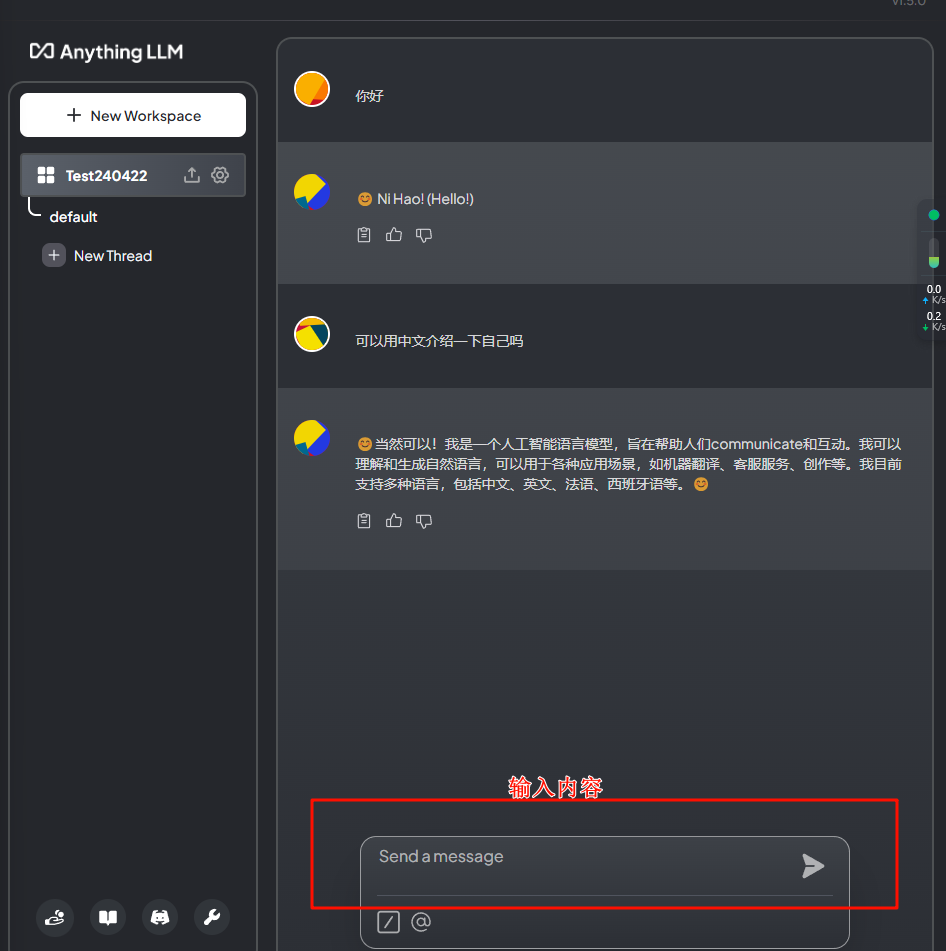
此时你就有了自己本地的语言模型了
是不是很简单,费时间的地方其实就在下载模型的时候,本来想用open webui,但是电脑没有搞docker,就用angthingllm了,后续有空搞个docker用open webui
如果模型实在下不下来,也可以搞离线模型
windows系统下ollama存储模型的默认路径是c:\users\wbigo.ollama\models,一个模型库网址:
挺全的,但是说实话,llama3-8b我感觉挺拉胯的,可能英文好一些,中文的话使用不如qwen
